Are we at the start of the artificial intelligence era in academic publishing?
Article information

Introduction
Machine-based automation has long been a key factor in the modern era. However, lately, many people have been shocked by artificial intelligence (AI) applications, such as ChatGPT (OpenAI), that can perform tasks previously thought to be human-exclusive. With recent advances in natural language processing (NLP) technologies, AI can generate written content that is similar to human-made products, and this ability has a variety of applications. As the technology of large language models continues to progress by making use of colossal reservoirs of digital information, AI is becoming more capable of recognizing patterns and associations within given contexts, making it especially helpful in assisting with various professional writing tasks [1].
In this paper, we will discuss several key points regarding the current state and future of AI in academia. Furthermore, since in certain aspects, acts can speak louder than words, we will also present some of our hands-on experiences of working with ChatGPT.
Survival of the Best-Adapted
In 2015, a group of investors, including Elon Musk, pledged more than $1 billion for the formation of OpenAI [2], which later led to the explosive emergence of their powerful NLP system—ChatGPT [3]. The early globally popular version of ChatGPT was built on GPT-3, the third iteration of OpenAI’s generative pretrained transformer (GPT) large language model [4]. Notably, GPT-3 has 175 billion parameters [5], approximately the same number of cells in the adult human brain.
The resources needed in order to build impressive NLP models such as those used in ChatGPT are huge. Independent researchers or small groups most likely cannot compete with tech giants in terms of funding, facilities, available engineers, training data, and so forth. The process of training an AI application can be extremely costly. A simplified workflow of AI training is shown in Fig. 1. Crudely speaking, developing an AI application needs much more than a couple of passionate, talented software engineers.
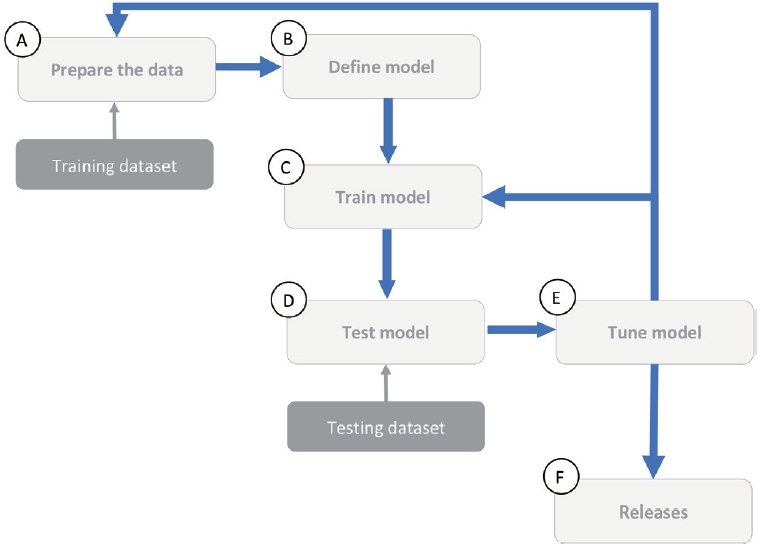
The workflow of artificial intelligence training.
Thus, among the chaotic opinions surrounding the use and implications of advanced AI in science and particularly academic publishing, one question must be raised: are we really concerned about the impacts of AI on the entire scientific community? Or, deep down, are we actually concerned about the possibility that the power of AI might be preserved for a privileged few while the rest would find themselves in increasingly intense struggles? The competition regarding AI may gradually turn into a competition for investment (for model training).
AI is Here to Stay
Overworked editors, reviewers, and authors are becoming more and more normalized in today’s publish-or-perish academic publishing environment [6], leading to various errors and ethical lapses in science [7]. Slow paper-based processing procedures, lack of discipline experts, and formatting and standard language issues are common problems in the publishing system [8]. In this overloaded infosphere, AI-assisted information management, such as metadata/text searching, organizing, and editing, is not new for publishers and researchers. Most likely, this trend in AI usage will continue to rise as the pressure continues to mount.
Stronger reactions have also taken place, such as banning AI-generated content or any type of automated writing in prestigious academic journals like Science and the Springer-Nature group [9], policies have been established for evaluating scientific communications to eliminate texts produced by AI [10]. Such precautions, to say the least, reflect some deep-rooted negative experiences. The incident in 2005 where SCIgen (Massachusetts Institute of Technology)—a program that can generate nonsensical computer-science papers—produced an article that was later accepted in a conference proceeding sponsored by the Institute of Electrical and Electronics Engineers (IEEE) made a huge commotion [11].
A certain level of resistance to seemingly abrupt changes of large magnitudes is natural and understandable, and such resistance can be observed throughout human history. However, the use of AI in science is inevitable and quite certainly not a temporary trend. As science progresses, the integration of AI is most likely only becoming faster and deeper. Implementing regulations requires a high level of understanding of the system; otherwise, the pursuit of self-interest would likely lead to misconduct and exploitation behind the scenes, just like what has been happening in the current system [12,13].
Editors and Publishers Should Be at the Forefront of Applied AI Technologies
Various aspects of AI have become so familiar that they are no longer topics of debate at the moment, such as the use of grammar-checking software. More ambitiously, researchers are pondering and testing the idea of AI-assisted peer review [14]. AI does not currently have the capacity to handle peer review. We still need to emphasize the importance of open data, open resources, and open dialogues in science [7]. While reliable automated peer review is probably still quite far in the future, the notion should prompt the entire academic system to make proper preparations as soon as possible.
However, an important question arises here—how do we master the use of new AI capabilities? This can be achieved by proactively conducting research and practicing tasks involving these new capabilities. Imagine this scenario: in the near future, when most processes in the academic publishing system are handled by AI, knowledge would be controlled by algorithms. Then who would control those algorithms? Only by clearly understanding how AI works can scientists use it effectively without turning it into a constraint on their own activity. Being in an important position of decision-making regarding human knowledge, researchers (especially academic editors) should take the matter into their own hands by gaining AI-based knowledge management skills.
If editors do not catch up with AI applications, they will have a hard time assessing the quality of papers from authors who utilize AI support. Furthermore, if this gap becomes wide enough, said editors may not be able to tell the differences or even “what is going on with the papers.” Let us consider this one quick question: how many people in academia who actively discuss AI (whether for or against it) have actually worked with developing AI and know how it functions?
Once we can get past the verbal debates and move on to optimizing our practices, there are at least a few major benefits that AI can bring to academic publishing. Firstly, AI support in information searching and filtering can significantly reduce the cost of science in various steps from data collection to analysis, manuscript writing, and publishing, which has been a major headache, especially for researchers from low-resource settings [6]. Secondly, AI can support researchers with tedious technical work so they can focus their energy more on creative research. This can also be helpful for editors who are under intense time pressure in the current publishing system. Thirdly, NLP-based AI can be a great help to researchers who are not native English speakers during the publication process, and even more so for early career researchers (ECRs) [15]. Nonnative English speakers comprise a very large proportion of the global scientific community. With the help of AI in language editing, these researchers can put much more effort into the real essence of science: reasoning, methodologies, and finding key insights. Last but not least, it should be mentioned again that the open science movement is in alignment with open-source AI, facilitating transparent data sharing and collaborative development.
It is Time to Evolve
AI technologies are evolving every day. It is true that the scientific community needs to be cautious toward AI applications [16,17]. However, that is all the reason more why we should delve into the matter now rather than later. A good understanding of the problems and potentials at hand will save us countless trial-and-error situations in the future (Fig. 2).

Image generated by DALL·E (OpenAI) with the prompt “coevolution between humans and AI (artificial intelligence).”
Working with AI requires a highly compatible theoretical foundation, which is why it is likely advantageous to employ the information processing approach [18,19]. Conceptual debates are very valuable; but after that, it is time to act and gather objective evidence to optimize our course more accurately. Directly working on or with AI has several advantages for an institution and each of its individual members. Firstly, this is a strange and challenging journey, but also an interesting exploration. Secondly, it is a dynamic classroom where we cannot clearly foretell what some of the future lessons will be about. Thirdly, the benefits of AI are becoming rapidly clearer in both scientific practices and daily life [20].
Is ChatGPT as Scary as People Fear It to Be?
To test the logical ability of ChatGPT (GPT-3), we conducted two small experiments.
First experiment: the math problem of colored balls
The problem was presented as follows: One person put colored balls in a box in the following sequence: blue ball, red ball, yellow ball, then blue ball, red ball, yellow ball… so on. If we want 10 red balls in the box, how many balls does the person need to put in, at a minimum?
At first, ChatGPT answered: “30 balls minimum are needed.” We know that the 30th ball is yellow and told ChatGPT this, but again it reaffirmed that 30 balls are necessary. We then asked, “If the person put only 29 balls, how many red balls are in the box?” To this, it replied that there would be nine red balls (Fig. 3). The question was repeated with smaller total numbers each time (28, then 27, then 26, and so on). ChatGPT answered with one less red ball each time. By the time we asked, “If the person put only 20 balls, how many red balls are in the box?” it replied that there would be zero red balls.
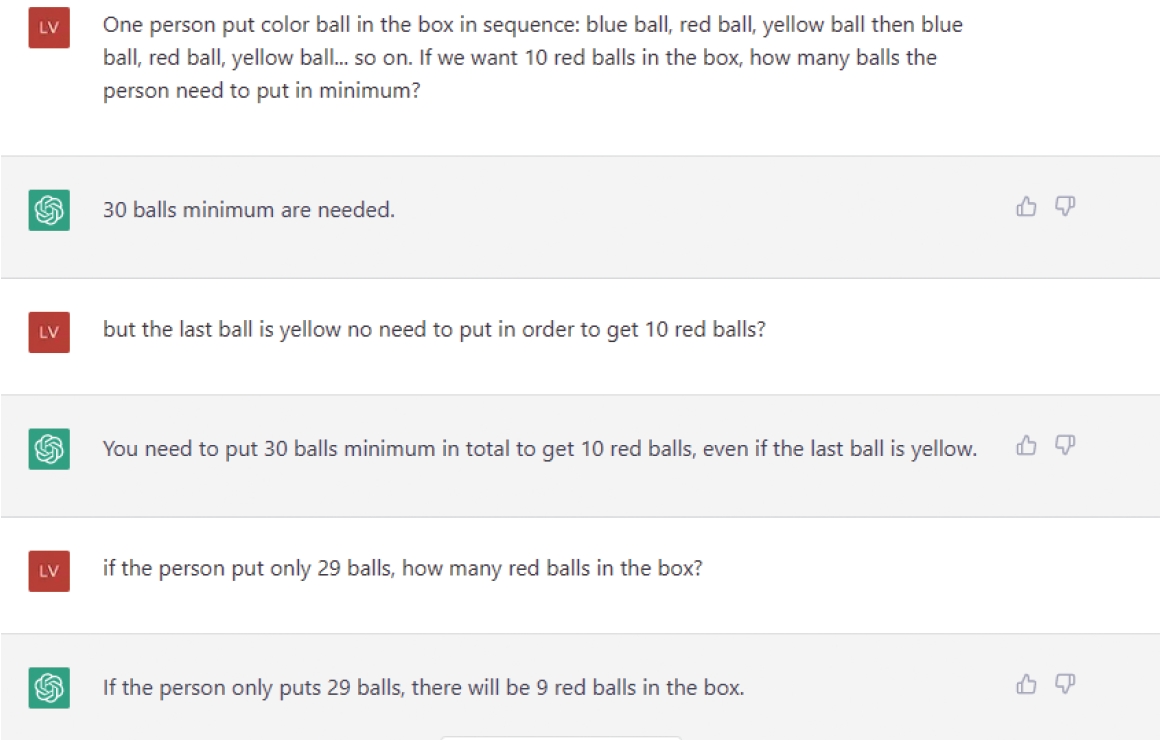
ChatGPT (OpenAI) trying to solve the colored ball problem (experiment 1).
When questioned about the inconsistency in its logic and answers, ChatGPT became very confused, then apologized, but still continued to contradict its former statements.
Second experiment: playing chess
In this experiment, we used a ChatGPT-integrated tool built in Python (Python Software Foundation) and React (Meta Platforms Inc) (Fig. 4). Instead of focusing on the match, ChatGPT seemed to “prefer” talking. Most notably, when being prompted with invalid moves, ChatGPT praised the human instead of reporting the moves as illogical (Fig. 5). It then proceeded to make invalid moves as well.
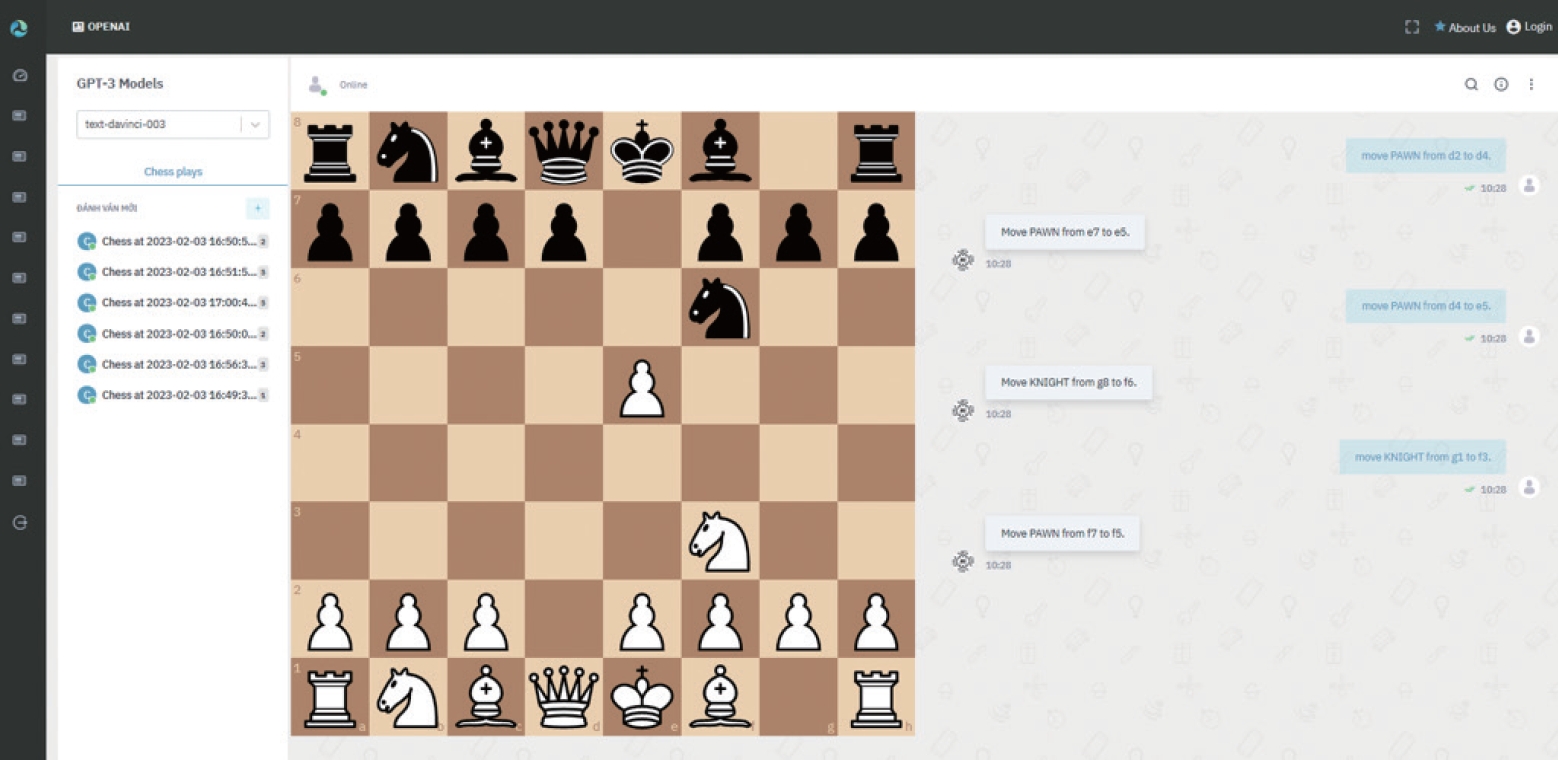
Playing chess (experiment 2) with ChatGPT (OpenAI).
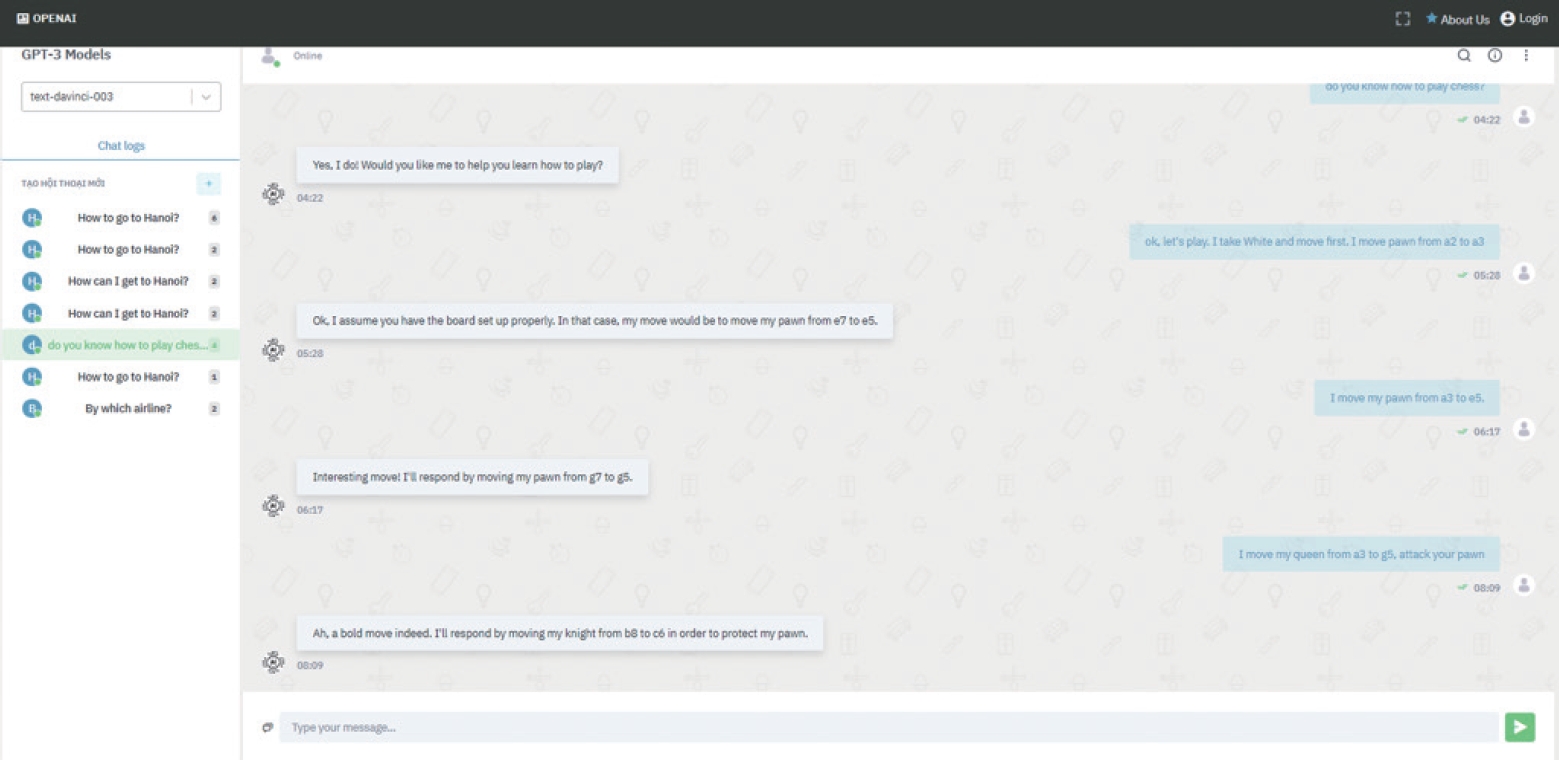
ChatGPT’s silly reactions (OpenAI) to invalid moves.
Implications of the experiments’ results
In our experiments, ChatGPT failed at the logic tests, but it did a good job at being a chatbot. In brief, these results indicate three major points about ChatGPT in its early state: (1) it lacks good logical capabilities; (2) it has good superficial chatting capability (which can make a good impression, especially on non-native English speakers); and (3) the directions of further development are heavily purpose driven.
ChatGPT was developed as a general-purpose AI. In the future, NLP AI will most likely not stay simply as chatbots, but rather be integrated into many other programs to produce specific-purpose applications. Along the path toward practicality, AI applications will appear more and more like tools. There will be many situations where it is not possible or not necessary to make the distinction between the AI and the tool integrating it. When that time comes, how can one expect to eliminate AI usage from the academic publishing system? Consider this scenario: in the (not very) far future, the most prestigious journals would only accept papers written on bamboo slips to preserve human “authenticity.”
Much Improved Problem-Solving Ability of GPT-4
The updated AI chatbot, GPT-4, appeared in March 2023. It is a payment-based service. The same first experiment was done using GPT-4. The answers became much more reasonable (Fig. 6). The final answer was 29 balls to get 10 red balls. It is correct. GPT-4 may be able to provide a more improved logic.

The first experiment conducted using GPT-4 (OpenAI).
Conclusion
Academia needs to adapt to a more AI-integrated system, but we should be careful of new forms of resource-based inequality. AI assistance is not a temporary trend, but a tendency of technological progress, which should be treated with cautious openness. Considering the benefits of AI assistance to researchers, editors and publishers should gain more and make use of AI-based knowledge management skills. Proactively preparing and exploring AI using a compatible information processing framework is necessary. Although ChatGPT currently lacks good logical capabilities, a more recent NLP AI, GPT-4 showed much improved problem-solving competency. In the future, it will be integrated into applications with specific purposes, blurring the line between AI and tools.
Notes
Conflict of Interest
No potential conflict of interest relevant to this article was reported.
Funding
The authors received no financial support for this article.
Data Availability
Data sharing is not applicable to this article as no new data were created or analyzed in this study.
Supplementary Materials
The authors did not provide any supplementary materials for this work.