Characteristics of retracted articles based on retraction data from online sources through February 2019
Article information

Abstract
Purpose
Although retractions are commonly considered to be negative, the fact remains that they play a positive role in the academic community. For instance, retractions help scientific enterprise perform its self-correcting function and provide lessons for future researchers; furthermore, they represent the fulfillment of social responsibilities, and they enable scientific communities to offer better monitoring services to keep problematic studies in check. This study aims to provide a thorough overview of the practice of retraction in scientific publishing from the first incident to the present.
Methods
We built a database using SQL Server 2016 and homemade artificial intelligence tools to extract and classify data sources including RetractionWatch, official publishers’ archives, and online communities into ready-to-analyze groups and to scan them for new data. After data cleaning, a dataset of 18,603 retractions from 1,753 (when the first retracted paper was published) to February 2019, covering 127 research fields, was established.
Results
Notable retraction events include the rise in retracted articles starting in 1999 and the unusual number of retractions in 2010. The Institute of Electrical and Electronics Engineers, Elsevier, and Springer account for nearly 60% of all retracted papers globally, with Institute of Electrical and Electronics Engineers contributing the most retractions, even though it is not the organization that publishes the most journals. Finally, reasons for retraction are diverse but the most common is “fake peer review”.
Conclusion
This study suggests that the frequency of retraction has boomed in the past 20 years, and it underscores the importance of understanding and learning from the practice of retracting scientific articles.
Introduction
Background: Retraction is described by the Committee on Publication Ethics as a mechanism for correcting the literature and alerting readers to publications that contain serious flaws or erroneous data to the extent that their findings and conclu-sions cannot be relied upon [1]. However, most readers and scientists regard retraction as an unfortunate negative outcome of the scientific enterprise. Retraction is seen as a source of embarrassment for all involved [2]. This is partially due to the public perceptions associated with the phenomenon: adverse consequences to the authors, wasted funds, wasted time and effort of the host institutions, and loss of the public’s trust when the reputation of science is tainted by fraud [3], to name just a few.
It is thought that retraction can be an opportunity for learning and improvement [4]. Future researchers can learn from the reasons behind retraction [5]. Publicly available retraction notices represent the fulfillment of the social responsibilities of journals and publishers [6]. Open review communities, such as PubPeer, can offer better monitoring services to keep problematic studies in check.
Specific goals: To better facilitate this truly powerful and positive function of retraction, a comprehensive database of retraction will be highly beneficial. Useful insights can be drawn from retraction data by asking questions. How old is the phenomenon? Are some specific publishers/journals more prone to retraction? Are retractions concentrated in certain fields? When did retractions begin to become more visible to the world? How long does it take for a journal to issue a retraction? Hence, by extracting insights from a homemade retraction database, of which the sources were RetractionWatch, official publishers’ archives, and online communities, we aimed to answer the above questions and provide suggestions for changes in scientific publishing. By doing so, we can make use of the wisdom of the retracted papers and avoid issues associated with retraction altogether in the future.
Methods
Ethics statement: No informed consent was required because this is a literature-based study.
Study design: This is a descriptive study that utilized database analysis.
Setting: A rise in scholarly publication retractions has been seen in recent years, according to sources of information such as RetractionWatch and publishers’ retraction notices, which have fostered open discussions of retracted publications categorized by author, country, journal, subject, and type [7,8]. Yet, the large amounts of data stored in different systems may easily lead to omissions in results obtained by searching manually.
To bolster the value of retraction data, we embarked on a project to replicate data retrieved from online platforms, such as RetractionWatch, online journal archives, and online discussion communities. We scanned retractions that these sources may have missed, then stored the data in a database. We built this database using SQL Server 2016 (Microsoft, Seattle, WA, USA) and employed a web crawler tool to scan the data (see the file retractionCrawler (code).pdf at https://osf.io/7ahsn/ in [9] for the code for the web crawler tool).
Then, articles collected by the web crawler tool were cleaned and assessed for duplication using the DOI and PubMed databases.
Additionally, a fuzzy matching Levenshtein distance algorithm was used to find articles that had titles with a similarity of more than 90% (see file and validData (code).pdf at https://osf.io/c2zvj/ in [9] for the code for data validation). A code snippet is provided in Fig. 1.
An example of code used.
After we eliminated 430 duplicate and incorrect records, the dataset contained 18,603 retractions, covering 127 research fields, from 1753 (when the first retracted paper was published) to February 2019. Raw data for the dataset of 18,603 retractions covering 127 research fields from 1753 until February 2019 are available in both .csv and .xlsx format in the files named retraction_18603.csv (https://osf.io/2kymw/) [10] and retraction_18603.xlsx (https://osf.io/a2w8h/), respectively [11]. The dataset, code examples, and all figures are stored and publicly available in the OSF system [9].
Statistical methods: Having organized the dataset, we then calculated descriptive statistics to present a clear overview of the practice of retraction in scientific publishing.
Results
Retractions were found in 4,289 journals belonging to 753 publishers (or publishing organizations). From the analysis of data through February 2019, 18,603 retractions were found. In the past, this phenomenon was rare. Table 1 presents information regarding the 10 oldest retracted articles, with the oldest dating back to 1756. The next recorded retraction occurred in 1927; following that, retractions were typically recorded as taking place every several years. The first five articles on this list are not accessible because no digitized document is available.

The list of the ten oldest retracted articles
The increasing number of retractions in recent years [12] may also reflect trends in time to retraction (the time from the publication of the article to the publication of the retraction note) [4]. We measured the time to retraction for the 10 articles with the longest time to retraction, and the longest interval before retraction was 80 years (Table 2). Four of the 10 articles listed below are not available online.

The 10 retracted articles with the longest interval between publication and retraction
Although the first retraction was issued in 1756, retraction only began to become more common in 1999, as shown in Fig. 2, with 2010 being an anomaly.

Number of retracted articles per year since 1999.
The number of retractions and the numbers of publishers, journals, countries, and fields in which retraction decisions were made per year are reported in Table 3. Despite the increase in journals issuing retractions in recent years, the number of retractions per retracting journal has not increased. As shown in Table 3, in 2010, 4,867 papers were retracted by 401 journals or publications associated with 92 publishers. The authors of articles retracted that year came from 70 different countries, and their papers covered 118 research fields.
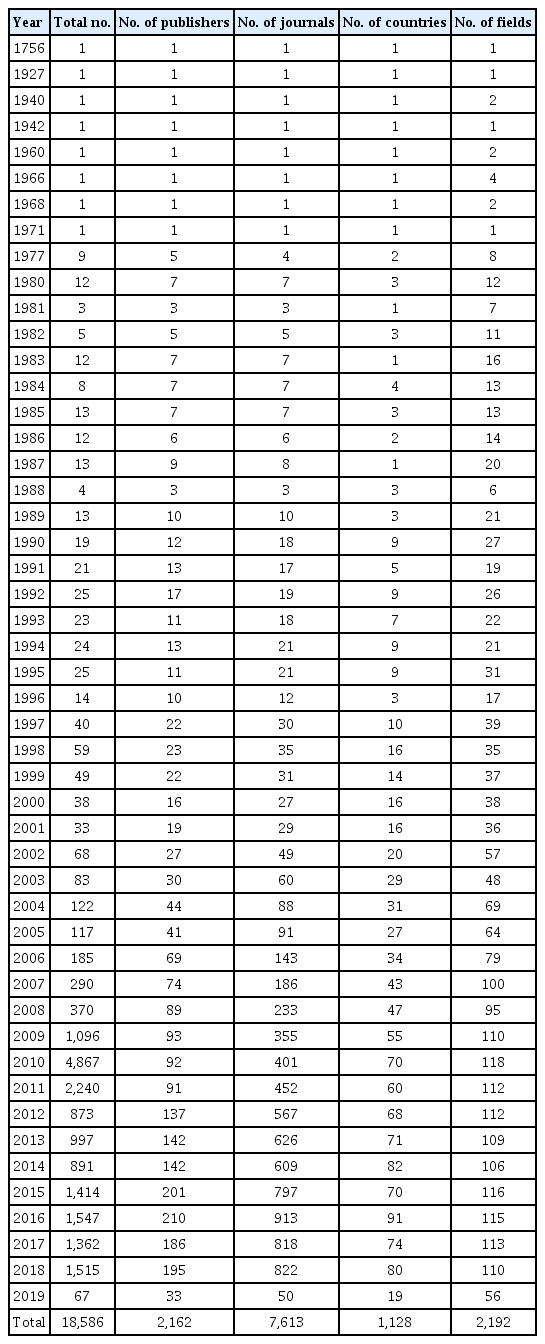
Number of publishers, journals, countries, and fields in which retraction decisions were made by year
Among the 753 publishers with retracted papers, the highest number of papers belonged to the Institute of Electrical and Electronics Engineers (IEEE), with 6,763 retracted articles. Elsevier had the most journals that have had papers retracted: 877 journals covering 114 research fields. The IEEE, Elsevier, and Springer accounted for 56.81% (10,569 of 18,603) of all retracted papers globally. Basic data concerning the publishers with the most retractions are given in Table 4.

Publishers with the largest number of retracted papers
Fig. 3 illustrates the distribution of the number of retracted papers by 2017 journal impact factor (JIF). It indicates that 7,836 out of 18,603 papers were published in journals with a JIF, of which more than three-fourths were published in journals with a JIF of 5 or lower.
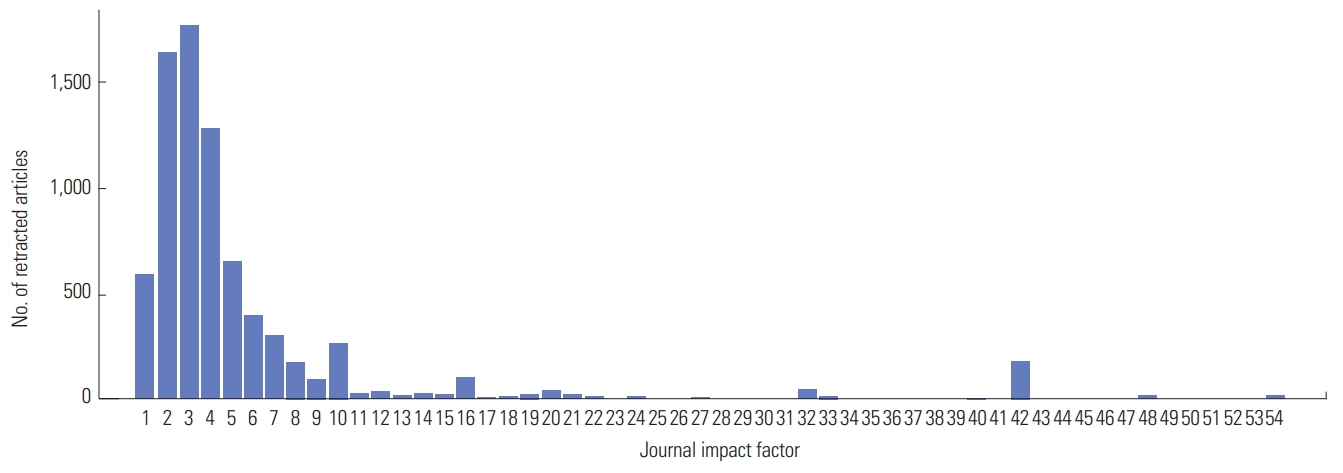
Distribution of the number of retracted articles by journal impact factor.
Data regarding retractions of papers in various fields are shown in Fig. 4.
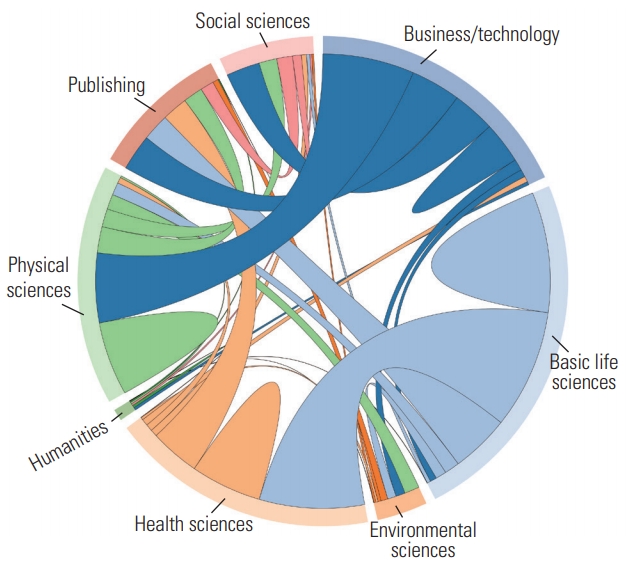
Chord diagram for retractions of papers in different fields.
China ranked first in the top 15 countries by number of retracted articles, as presented in Table 5.

Top 15 countries by number of retracted articles
A closer look at the top five countries showed a spurt in the retractions of articles by Chinese authors around 2010, as depicted in Figs. 5 and 6.
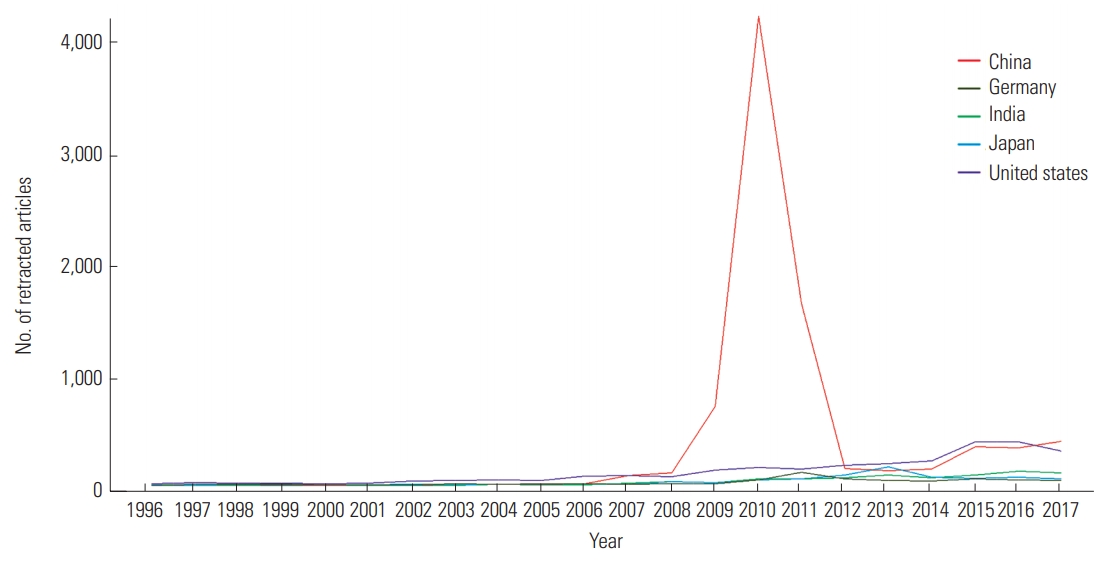
Top five countries according to the number of retracted articles by year.
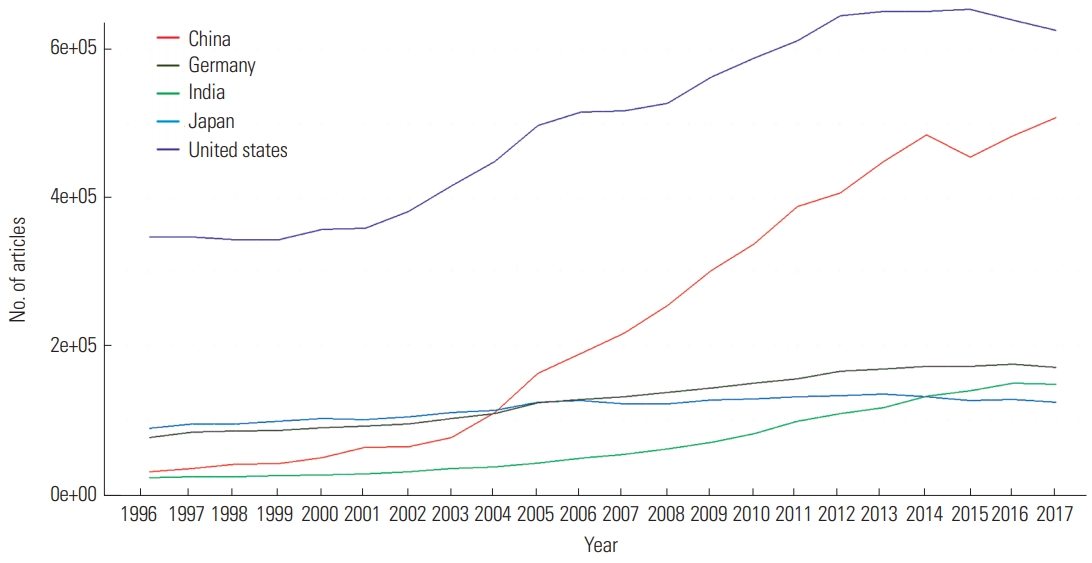
Number of articles published each year of the top five countries with regard to the number of retracted articles.
Discussion
Key results: RetractionWatch is among the few databases tracking retractions exclusively on the global scale; hence, making the best use of this resource can greatly benefit the scientific community. Recognizing this fact, we have collected a comprehensive database on scientific retractions from 1753 to February 2019 using SQL Server 2016 and homemade artificial intelligence tools. This database enabled us to answer the questions posed in this paper. We found that although retraction is an old phenomenon, with the first retraction of a paper dating back to 1756 (Table 1); it became a common practice in 1999, and the most retractions were issued in 2010.
Moreover, the longest duration that a retracted paper stayed in the literature was 80 years (Table 2). Most notably, the IEEE, Elsevier, and Springer together accounted for nearly 60% of all retracted papers, with the IEEE accounting for the most. Of the reasons for retraction, “fake peer review” was the most common. Additionally, our database noted a sharp rise in the number of retracted papers from China (Table 5). These insights suggest that future studies can continue to explore various aspects of retractions.
Interpretation: This rise of retraction that began in 1999 (as shown in Fig. 2) is nearly consistent with the findings of Brembs et al., which concluded that the retraction rate of articles had remained stable since the 1970s and began to increase rapidly in the early 2000s. They also saw the creation and popularization of a website dedicated to monitoring retractions in 2010 [13]. However, this increase may be a sign that journal editors are becoming more skillful at identifying and removing flawed publications [14].
Diverging from previous results that held that journals with higher impact factors have a higher rate of retractions [15], our finding showed an non-significant correlation between JIF and the probability of article retraction (Fig. 3). This result is consistent with Singh et al. [3], who found a statistically non-significant relationship between the impact factor and the number of articles retracted. Different fields also had different numbers of retracted papers (Fig. 4). The majority of retractions were associated with business and technology, physical sciences, basic life science, and the health sciences. Meanwhile, the social sciences, humanities, environmental science, and publishing accounted for a small portion of all retractions. The relationships among retractions in different fields is also presented in Fig. 4. For instance, basic life sciences and health sciences had a significant number of shared retracted articles. In fields with few retractions, most of the retracted articles were shared with fields with high numbers of retractions.
The reasons for retraction can be diverse, and one paper is usually retracted for multiple reasons [4,7]. Since 2012, “fake peer review” has become a major reason, with 676 retractions for that reason during the last 7 years. About 30% (5,602) of retracted papers had undergone some investigation (Office of Research Integrity official investigation, investigation by a third party, investigation by a company/institution, or investigation by a journal/publisher) before being retracted. The findings of Qi et al. [8] also indicate that the number of retractions due to fake peer review differs among journals and countries; a majority (74.8%) of retracted papers were determined to be written by Chinese researchers.
This result may be due to China’s current national situation (Table 5 and Figs. 5, 6). Greater amounts of funding and awards for conducting scientific research make researchers more eager to publish; however, measures to enforce publishing ethics may not have caught up [8]. However, it is important to note that when considering the number of retractions per publication and the amount of research funding, respectively, Iran and Romania are the top countries [16].
Limitation: This article is not exempt from limitations. First, this study mainly employed descriptive statistics, which serve only to provide an overview and do not dive into any specific issue. Thus, future studies should make use of the resources provided by this report and focus on tackling specific problems, such as reasons for retraction or case studies of publishers or countries. Different statistical approaches, such as frequentist statistics [17] or Bayesian statistics [18], should be used. Analyses of these specific topics using different statistical methods will yield a more in-depth understanding of the practice of retraction. Second, due to paywalls, our artificial intelligence tools were unable to scan beyond basic information unless the retracted articles were open-access and available in HTML format. Similarly, this study used the 2017 JIF, also because of an accessibility issue. In the future, new technology and open-access policies of publishers may enable us to access more information.
With regard to lessons that can be learned from the above findings, what we present is only a macro-level view of the entire practice of retraction. The data, when organized and analyzed properly, will be much more useful for various stakeholders. As an example, the story of China and the drastic 2010 peak in retracted articles suggest that countries that are newcomers to the academic world should take care to avoid getting too caught up in productivity boosts, particularly in developing countries, where policy failure can be extremely consequential [19]. The provision of science financing and grants is, of course, a welcome action on the part of the government [20]; however, science policies ought not to incentivize researchers to sacrifice quality for quantity. In the face of the increase in the frequency of retractions across all fields in global academia, nurturing a culture of honesty and humility is just as important as output. Editors and publishers, as well as researchers and policy-makers, have something to learn from the story of retraction. Publishers can hold the key to mitigating the fierce competition on a playing field often leveled against emerging countries, thus supporting more sustainable practices in scientific publishing [21].
Conclusion: In essence, science is a continuous process of trial and error, and only by accepting the possibility of failure can a scientist make progress [22]. Thus, this study offers an overview of retraction offered from various perspectives, in which the data was examined with regard to articles, publishers, fields, and countries. This overview suggests that retraction has boomed in the past 20 years, and that the lessons that can be learned from retractions must be taken more seriously.
Notes
Conflict of Interest
No potential conflict of interest relevant to this article was reported.
Data Availability
Raw data for the dataset of 18,603 retractions covering 127 research fields from 1753 until February 2019 are available in both .csv and .xlsx format under the files named retraction_18603.csv (https://osf.io/2kymw/) and retraction_18603.xlsx (https://osf.io/a2w8h/), respectively. The dataset, code examples, all figures, and other files are deposited and publicly available in OSF (https://osf.io/pbwv3/).
Acknowledgements
This research is funded by the Vietnam National Foundation for Science and Technology Development (NAFOSTED) under the National Research Grant no. 502.01-2018.19. We would also like to thank RetractionWatch for their contributions to science.