Ethical challenges regarding artificial intelligence in medicine from the perspective of scientific editing and peer review
Article information

Abstract
This review article aims to highlight several areas in research studies on artificial intelligence (AI) in medicine that currently require additional transparency and explain why additional transparency is needed. Transparency regarding training data, test data and results, interpretation of study results, and the sharing of algorithms and data are major areas for guaranteeing ethical standards in AI research. For transparency in training data, clarifying the biases and errors in training data and the AI algorithms based on these training data prior to their implementation is critical. Furthermore, biases about institutions and socioeconomic groups should be considered. For transparency in test data and test results, authors should state if the test data were collected externally or internally and prospectively or retrospectively at first. It is necessary to distinguish whether datasets were convenience samples consisting of some positive and some negative cases or clinical cohorts. When datasets from multiple institutions were used, authors should report results from each individual institution. Full publication of the results of AI research is also important. For transparency in interpreting study results, authors should interpret the results explicitly and avoid over-interpretation. For transparency by sharing algorithms and data, sharing is required for replication and reproducibility of the research by other researchers. All of the above mentioned high standards regarding transparency of AI research in healthcare should be considered to facilitate the ethical conduct of AI research.
Introduction
Artificial intelligence (AI), which makes use of big data based on advanced machine learning techniques involving multiple layers of artificial neural networks (i.e., deep learning), has the potential to substantially improve many aspects of healthcare [1]. With new technological developments, new ethical issues are also introduced. Many international authorities, including some in the medical field, are attempting to establish ethical guidelines regarding the use of AI [2-5]. Healthcare is a field in which the implementation of AI involves multiple ethical challenges. Notable ethical issues related to AI in healthcare are listed in Table 1 (not exhaustive) [1,2,6-22]. AI is unlikely to earn trust from patients and healthcare professionals without addressing these ethical issues adequately.

Notable ethical issues related to AI in healthcare (not exhaustive)
Some of these ethical issues are relevant to the scientific editing and peer review processes of academic journals. Transparency is one of the key ethical challenges surrounding AI in healthcare [23]. The scientific editing and peer review processes of medical journals are well positioned to ensure that studies on AI in healthcare are held to a high standard of transparency, thereby facilitating the ethical conduct of research studies and the ethical spread of knowledge. The role of peer-reviewed medical journals in this field is particularly important because many research studies on AI in healthcare are published without peer review through preprint servers, such as arXiv.org, most of which are not accepted by the medical field [1,24]. This article highlights several specific areas in research studies on AI in healthcare that currently require additional transparency, explains why additional transparency is needed, and discusses how to achieve it from the perspective of scientific editing and peer review. This article can serve as a guide for authors and reviewers to ensure that research reports on AI in healthcare are held to a high standard of transparency. However, it is not intended to serve as an all-inclusive guide for writing and reviewing research articles on AI in healthcare, nor is it intended to provide general ethical guidelines for AI in healthcare. More general guides can be found elsewhere [2-5,25].
Transparency in Training Data
Reports of research studies on AI in healthcare should explain the details of how authors collected, processed, and organized the data used in studies thoroughly (with specific mention of dates and medical institutions), in addition to describing the baseline demographic characteristics, clinical characteristics (such as the distribution of severity of the target condition, distribution of alternative diagnoses, and comorbidities), and technical characteristics (such as techniques for image acquisition) of the collected data thoroughly to help readers understand biases and errors in the data [13,23,25,26]. In both academia and industry, researchers are praised for training increasingly sophisticated algorithms. However, relatively little attention is paid to how data are collected, processed, and organized [13]. Therefore, improvements in this area are needed. Several related guidelines are available to assist in transparent reporting [25,27-29].
Modern AI algorithms built using big data and multiple layers of artificial neural networks have achieved superior accuracy compared to past algorithms. However, current AI algorithms are strongly dependent on their training data. The accuracy of these algorithms cannot go beyond the information inherent to the datasets on which they are trained, meaning they cannot avoid the biases and errors in the training data. Because the datasets used to train AI algorithms for medical diagnosis/prediction are prone to selection biases and may not adequately represent a target population in realworld scenarios for various reasons (explained below), this strong dependency on training data is particularly concerning. Clarifying the biases and errors in training data and AI algorithms based on these training data prior to their implementation is critical, especially given the black box nature of AI and the fact that cryptic biases and errors can harm numerous patients simultaneously and negatively affect health disparities at a large scale [10].
Complex mathematical AI models for medical diagnosis/ prediction require a large quantity of data for training. Producing and annotating this magnitude of medical data is resource intensive and difficult [13,22,30,31]. Additionally, the medical data accumulated in clinical practice are generally heterogeneous across institutions and practice settings based on variations in patient composition, physician preference, equipment and facilities, and health policies. Many data are also unstructured and unstandardized in terms of both their final form and process of acquisition. Missing data are also relatively common. As a result, most clinical data, whether from electronic health records or medical billing claims, are poorly defined and largely insufficient for effective exploitation by AI techniques [16,32]. In other words, they are “not AI ready” [16,22,31,32], which makes the data collection and curation process even more difficult. Therefore, researchers who collect big medical data to develop AI algorithms might rely on whatever data are available, even if these data are prone to various selection biases [13,30,33]. Existing large public medical datasets are also used for developing AI. However, few such databases are currently available, and most are small and lack real-world variation [2,25,32]. Additionally, any assumptions or hidden biases within such data may not be explicitly known [2,25,32].
Dataset shifting in medicine poses another challenge. In disciplines where medical equipment for generating data evolves rapidly (such as various radiologic scanners), dataset shifting occurs relatively frequently [2,9]. For example, if an AI algorithm is trained only on images from a 1.5-Tesla magnetic resonance imaging scanner, it may or may not output the same results for examinations performed using a 3-Tesla magnetic resonance imaging scanner.
Biases in medical data are sometimes macroscopic [2,10- 12,16]. For example, electronic health records and insurance claim datasets are records of patient clinical courses, but they also serve as a tool for healthcare providers to justify specific levels of reimbursement. Consequently, data may reflect reimbursement strategies and payment mechanisms more than providing an objective clinical assessment. As another example, health record data may contain biases for or against a particular race, gender, or socioeconomic group. However, in many cases, the biases are complex and difficult to anticipate [2,12]. Such biases may manifest as inadvertent discrimination against under-represented subsets of a population, limited interoperability (algorithms trained on patients from a single institution may not be generalizable across different institutions and populations), and the frame problem [2,10,17]. The frame problem is exemplified by a recent accident caused by an experimental autonomous driving car from Tesla that crashed into the trailer of a truck turning left, killing the driver, because it failed to recognize the white side of the trailer as a hazard [10]. Simply put, AI cannot classify what it is not trained on. This raises significant concerns in medicine because unexpected situations can occur in real-world clinical practice at any time, and such situations are not infrequent. Any anticipated biases in data, as well as any unintended consequences and pitfalls that can occur based on these biases, should be transparently disclosed in research reports.
Transparency in Test Data and Test Results
In addition to the points raised in the previous section regarding transparency of training data, there are several other points worth noting regarding the transparency of datasets for testing the performance of AI algorithms. Firstly, for the same reasons mentioned above, external validation (i.e., assessing the performance of an AI algorithm using datasets collected independently from the training dataset) is essential when testing the performance of an AI algorithm for medical diagnosis/prediction [10,13,17,18,25,26,33,34]. Computer scientists evaluate algorithms on test datasets, but these are typically subsamples (such as random-split samples) of the original dataset from which the training data were also drawn, meaning they are likely to contain the same biases [13,35]. Research reports should clearly distinguish preliminary performance evaluations using split subsamples from genuine external validations. The lack of adequate external validation for AI algorithms designed for medical diagnosis/prediction is a pressing concern [35]. According to a recent systematic review of the research studies published between January 1, 2018, and August 17, 2018, that investigated the performance of AI algorithms for analyzing medical images to provide diagnostic decisions, only 6% performed some type of external validation [35]. A clear editorial guide regarding external validation will promote adequate external validation.
Secondly, when describing the process of collecting test datasets, it is necessary to distinguish whether datasets were convenience samples consisting of some positive and some negative cases or clinical cohorts that adequately reflect the epidemiological characteristics and disease manifestation spectrum of clinically-defined target patients in real-world practice [36]. The former is referred to as diagnostic casecontrol design, while the latter is referred to as diagnostic cohort design [36-38]. For example, when testing an AI algorithm that detects lung cancer on chest radiographs, testing its performance on a dataset consisting of some cases with lung cancer and some cases without lung cancer is a diagnostic case-control design [36]. By contrast, a diagnostic cohort design defines the clinical setting and patients first by establishing eligibility criteria. For example, a study might consider asymptomatic adults aged X–Y years with Z-packs-per-year smoking history. Then, all (or a random selection) of those who fulfilled the criteria within a certain period are recruited and examined by the AI algorithm. It is recommended to perform a diagnostic cohort study in a prospective manner.
A diagnostic cohort is a better representation of real-world practice than a convenience case-control sample because it has a more natural prevalence of disease, more natural demographic characteristics, and a more natural disease manifestation spectrum including patients with disease-simulating conditions, comorbidities that may pose diagnostic difficulty, and findings for which the concrete distinction of disease versus non-disease is inappropriate [36]. Case-control design is prone to spectrum bias, which can potentially lead to an inflated estimation of diagnostic performance [33,39]. A diagnostic cohort design not only results in a less biased estimation of the clinical performance of an AI algorithm, but it also allows for the assessment of higher-level endpoints that are more clinically relevant, such as positive predictive value (or post-test probability), diagnostic yield, and the rate of false referrals [17,35,38].
A diagnostic cohort study using AI should describe patient eligibility criteria explicitly; it should also clarify the reasons and subject numbers for any incidents of individuals who were eligible but unenrolled, or those who were enrolled but were not included in the analysis of study outcomes [27,29]. Typical reasons for such incidents include technical failure, drop-out/follow-up loss, and missing reference standard information.
Finally, for the same reasons mentioned above, the performance of an AI algorithm may vary across different institutions [40-43]. Therefore, it is essential to use test datasets from multiple institutions and report all individual institutional results to assess the interoperability of an AI algorithm and generalizability of study results accurately. Underreporting of negative or unfavorable study results is a well-known pitfall in medical research in general; similarly, some researchers or sponsors of AI research studies may be inclined to report favorable results selectively. Underreporting of negative or unfavorable study results was a significant reason why the policy of prospectively registering clinical trials was first introduced in 2005 by the International Committee of Medical Journal Editors. Currently, numerous medical journals consider reports of clinical trials for publication only if they have been registered a priori in publicly accessible trial registries (e.g., clinicaltrials.gov) with key study plans.
Transparency through the full publication of the results of AI research is equally important [15,25,26,44]. A similar requirement for the prospective registration of studies for clinical validation of AI algorithms will help increase confidence in study results among patients and healthcare professionals, as well as in the process of regulatory approval. In fact, the requirement for prospective registration of diagnostic test accuracy studies has already been proposed by some medical journals [45]. Studies to validate the clinical performance of AI algorithms belong to the broader category of diagnostic test accuracy studies. Therefore, the adoption of this policy would have an instant effect.
Transparency in Interpreting Study Results
The interpretation of results in research reports on AI in healthcare should be explicit and avoid over-interpretation (also referred to as “spin”) [46]. Because AI in healthcare is a topic in which not only related professionals but also the public have considerable interest, the reporting of research studies should consider laypeople as potential readers. An explicit interpretation of study results without spin is critical to prevent misinforming the public or lay media. Spinning study results may make a study “look better.” However, excessive hype [1] that is generated inadvertently or exacerbated through misinformation will ultimately erode faith in AI for both the public and healthcare professionals. The scientific editing and peer review processes play an important role in building trust in AI by publishing clearer, more accurate information.
Typical examples of spinning study results include describing the results from split samples as external validation, claiming proof of clinical validity or utility for a limited external validation using diagnostic case-control design, and claiming evidence regarding the impact on healthcare outcomes based on accuracy results alone. Accuracy results obtained from test datasets split from an original dataset do not represent external validation and may only show technical feasibility at best [13,25,26,34,35]. High-accuracy results from external datasets in a case-control design may further support technical/analytical validity, but they are still not sufficient to prove clinical validity [25,36]. High-accuracy results from external datasets collected in a diagnostic cohort design without strong selection biases can support clinical validity more strongly [25,26,33]. However, such high-accuracy results cannot directly determine the impact of AI on healthcare and clinical utility [1,33,47]. One would need clinical trials focusing on health outcomes or observational research studies with appropriate analytical methods to account for confounders, preferably in the form of prospective design, to address the impact of AI on healthcare and clinical utility [1,33,48-53].
Additional Transparency by Sharing Algorithms and Data
Addressing the issues mentioned above would help to enhance the transparency of research studies on AI. However, the effects would be indirect. By contrast, sharing AI algorithms and data from a research study with other researchers or practitioners so they can independently validate the algorithms and compare them to similar algorithms is a more direct means of ensuring the reproducibility and generalizability of AI algorithms for greater transparency. Lack of sharing appears to be an important reason why innovative medical software solutions with clinical potential in most software research, including AI research, have largely been discarded and failed in the transition from academic use cases to widely applicable clinical tools [24,54].
Based on this phenomenon, one prominent medical journal in the field of AI in medicine has recently adopted a policy to strongly encourage making the computer algorithms reported in the journal available to other researchers [24]. Additionally, a body of researchers has recently published the FAIR Guiding Principles for scientific data management and stewardship to provide guidelines to improve the findability, accessibility, interoperability, and reuse of digital assets [55]. Scientific editing and peer review can facilitate such movements by embracing them. However, the proprietary nature of AI algorithms, as well as data protection and ownership, are issues that must be resolved carefully.
Conclusion
Healthcare is a field in which the implementation of AI involves multiple ethical challenges. AI in healthcare is unlikely to earn trust from patients and healthcare professionals without addressing these ethical issues adequately. Transparency is one of the key ethical issues surrounding AI in healthcare. A list of specific questions to ask to make studies evaluating the performance of AI algorithms more ethically transparent is provided in Table 2. Note that Table 2 is not a comprehensive checklist for reporting research studies on AI in healthcare. Further information and relevant checklists can be found elsewhere [56] and should also be referred to appropriately. The scientific editing and peer review processes of medical journals are well positioned to ensure that studies of AI in healthcare are held to a high standard regarding transparency, thereby facilitating the ethical conduct of research studies and spread of knowledge.
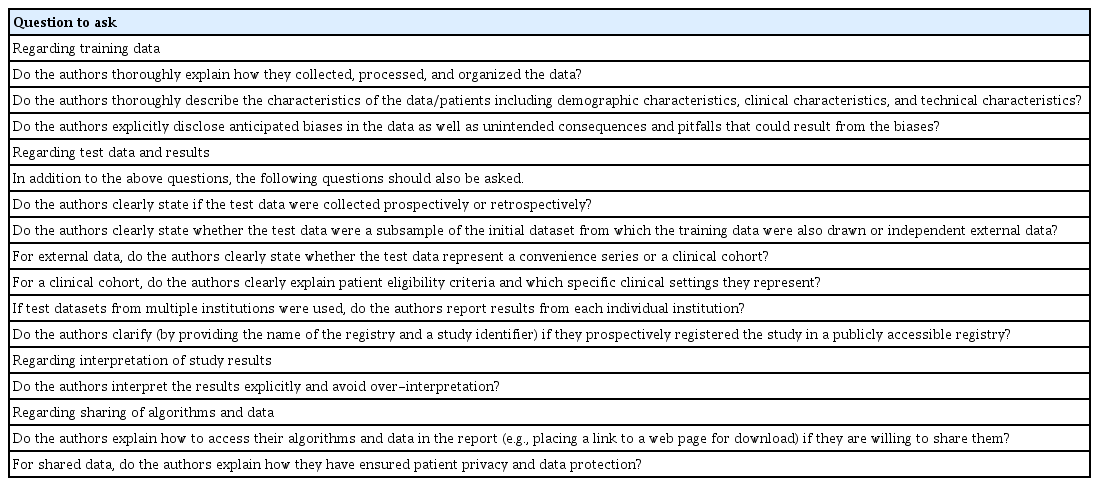
Questions to ask to improve ethical transparency in studies evaluating the performance of artificial intelligence algorithms
Notes
Conflict of Interest
No potential conflict of interest relevant to this article was reported.