Meeting: 45th Society for Scholarly Publishing Annual Meeting
Date: May 31–June 1, 2023
Venue: Oregon Convention Center and Hyatt Regency Portland, Portland, OR, USA and online
Organizer: Society for Scholarly Publishing
Theme: Transformation, trust, and transparency
This marked my first time attending a meeting organized by the Society for Scholarly Publishing (SSP). This year, the 45th SSP Annual Meeting was hosted at the Oregon Convention Center and Hyatt Regency Portland (Portland, OR, USA). The theme of the meeting was “transformation, trust, and transparency.” The event spanned 2 days, May 31 and June 1, 2023, and featured numerous concurrent sessions. The meeting was conducted paperlessly, utilizing Whova (Whova Inc, https://whova.com/), an all-in-one platform for hosting and planning virtual conferences. This article is based on the 45th SSP Annual Meeting, and I have incorporated relevant concepts, background, and history where necessary throughout the report.
Before the meeting commenced, attendees had the opportunity to leave messages using Whova. These could be simple greetings to other participants, or they could express specific queries or interests, such as a visit to Powell’s Books, a breakfast gathering, jogging, and more. This platform allows for interaction with others, including organizers, fellow panelists (if you are a panelist), and poster presenters. While this tool is convenient, without a hardcopy backup and some training in using Whova, I found it challenging to access information quickly, especially during the four parallel sessions. In addition to the talks, I thoroughly enjoyed my brief visit to Powell’s Books, reputedly one of the largest bookstores in the world. The meeting kicked off with an “industry session” that showcased publishers and associated businesses. Despite my initial modest expectations, I found this session to be highly informative.
Research Square introduced AJE Digital Editing (Research Square, https://www.aje.com/services/digital/), an artificial intelligence (AI)-powered tool that has been trained on millions of edits by professional editors. This tool is designed to expedite the publishing process and make it more equitable. As a non-native English speaker, I, along with many others, have taken a keen interest in this development. We often encounter difficulties in enhancing the quality and clarity of our manuscripts, focusing not on the results, but on the content. According to a representative from Research Square, AJE’s Digital Editing can effectively identify unclear or incorrect sentences within the context of technical and field-specific language, while also making improvements at the phrase level. The initial pilot of digital editing was launched on submissions to Scientific Reports in August 2022.
Straive presented a talk on how the AiKira platform (Straive) can enhance publishing workflows, titled “The Future of Publishing Workflows: How the AiKira Publishing Platform from Straive is Setting the Standard.” The discussion highlighted AuthorMate (Straive), a service designed to support authors, and Research Integrity (Straive), which ensure credibility and integrity in academic content. The talk also introduced Reviewer Finder (Straive), a tool that uses advanced algorithms to streamline the process of selecting reviewers, and AiKira, a next-generation publishing platform with an open architecture.
TNQ Books hosted a session titled “ChatGPT and other LLMs: Should We Celebrate or Be Afraid of These Technologies?” The session was moderated by Abhigyan Arun, the chief executive officer (CEO) at TNQ Technologies, and featured two panelists, Ravi Pardesi and Neelanjan Siniha [1]. ChatGPT (OpenAI), a generative AI model, is notably different from its predecessors and has recently emerged with the potential to disrupt the current status quo. Alongside ChatGPT, other large language models (LLMs) such as Google’s Bard and Facebook’s LLaMA are also transforming traditional business models. These models come in various forms, including proprietary (OpenAI), open source (Meta AI), or applicationfocused (Adobe Firefly, stability.ai, SciBERT). It is clear that a significant number of academic publishers and business service providers are exploring the potential of these technologies and considering how they might impact the future ecosystem. While these innovations offer certain benefits, they also pose significant risks and challenges that need to be carefully considered before adoption. As such, these changes are being viewed with a mix of optimism and caution. This is particularly true in areas such as ethics and legality, quality and specificity, security, cost, reliability, performance, scalability, and integration. Regulatory issues also add to the complexity of the situation.
Nonetheless, hundreds of professionals in artificial intelligence and other notable individuals signed the following concise Statement on AI Risk on May 30, 2023: “Mitigating the risk of extinction from AI should be a global priority alongside other societal-scale risks such as pandemics and nuclear war.” The statement can be found on the website of the Center for AI Safety, a nonprofit organization dedicated to AI research and activism [2].
A session, entitled “Maximizing Data Sharing Policy Impact through Implementation, Compliance, and Support Workflows” featured a discussion by the panelists, Ginny Herbert (editorial development manager), Graham Smith (open data program manager, Frontiers), Rebecca Grant (Head of Data and Software Publishing, Taylor & Francis Group LLC) and Tim Vines (founder and CEO, Dataseer). Over the past few years, the landscape of data sharing has undergone significant transformation. With the growing demands for research transparency and efficiency, data sharing policies are gaining popularity among both funders and journals. The data sharing commitments outlined in the 2022 Nelson Memorandum [3] are poised to accelerate the adoption of these policies. This is because funded researchers are striving to meet these requirements, and publishers are adapting to the changing needs of the research community.
The session began with a series of questions, as follows: What policy changes are on the horizon? Will institutions become involved? Will you choose to be reactive or proactive? What does being proactive entail? Clearly, we need to closely monitor and understand the current situation to effectively answer these questions. Over time, it has become apparent that journals are shifting from lenient data sharing policies to more rigorous ones.
Most, if not all, research scientists believe that data sharing is crucial for adhering to funding policies and meeting the requirements for journal submission policies. Conversely, from the perspective of scholarly publishers, it is necessary to establish internal training and support systems to integrate data policies and facilitate the evaluation of author compliance. It is worth noting that publishers should assess the impact and challenges of fully open data policies in comparison to the constraints of journal data sharing policies, as well as the degree to which they promote the sharing of reusable data. Additionally, it may be beneficial to consider how advances in technology can strengthen data sharing policies.
Publishers and journals need to specify which elements of data sharing are not included, such as laboratory notebooks, preliminary analyses, completed case report forms, manuscript drafts, peer reviews, communications with colleagues, and physical objects like specimens. The policy often emphasizes the importance of metadata as a crucial part of data sharing and management plans. For example, the US National Institutes of Health (NIH) includes the following elements in their data management plan [4]: data type; related tools, software, and/or code; applicable standards; data preservation, access, and associated timelines; considerations for access, distribution, or reuse; and oversight of data management and sharing. The key NIH resource website can be accessed at https://sharing.nih.gov.
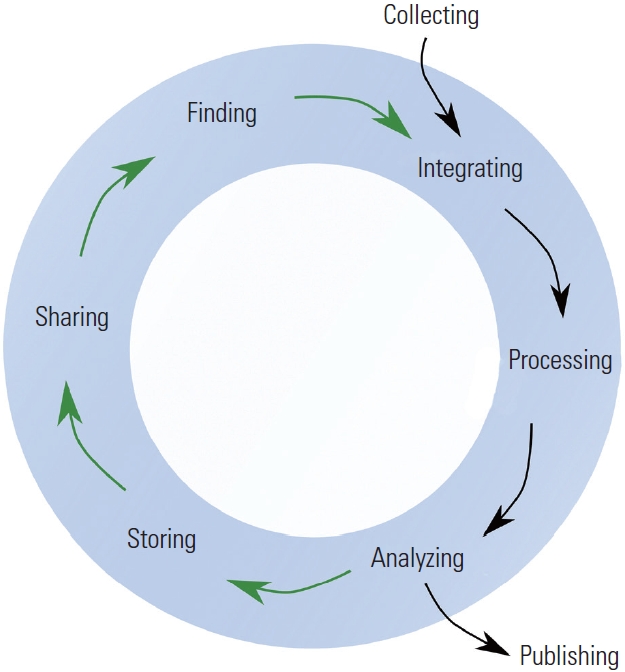
Fig. 1 provides an excellent example of the processes and concepts involved in data sharing, offering a clear and familiar framework [5]. The discussion also included the FAIR (Findable, Accessible, Interoperable, Reusable) and CARE (Collective Benefit, Authority to Control, Responsibility, Ethics) principles. The FAIR principles, which guide scientific data management and stewardship, were introduced in 2016 through a collaborative effort involving academia, industry, funding agencies, and scholarly publishers. The goal was to establish a standard for data accessibility and reusability from both human and machine perspectives. This often pertains to the data itself and its associated metadata, which provides descriptive and contextual details to aid understanding and organization [6]. While the FAIR principles focus on the data, the CARE principles complement and expand upon them. Of note, indigenous peoples, asserting sovereignty over the application and use of indigenous data, can become uneasy when the sole objective is to increase data shareability [7]. In this context, it is worth mentioning that the CARE Principles for Indigenous Data Governance were developed by Global Indigenous Data Alliance (GIDA) in 2019.
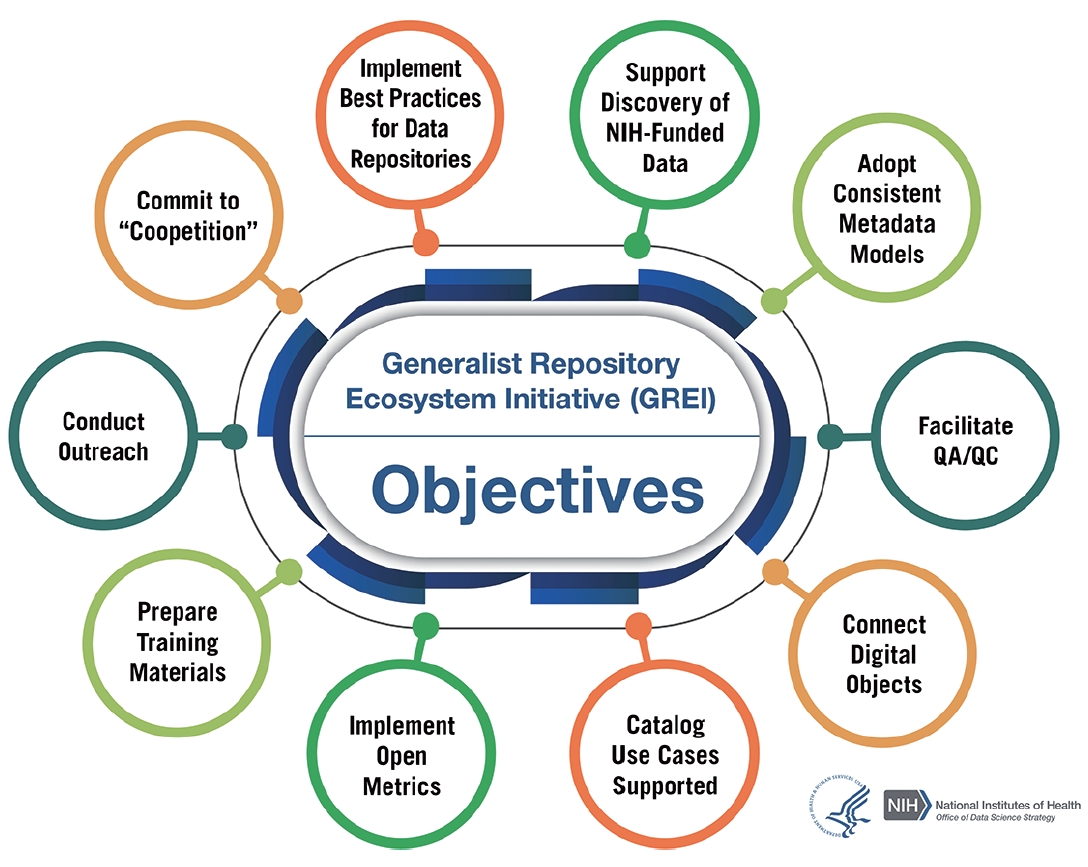
Due to the release of the Data Management and Sharing policy by NIH, most grantees funded after January 23, 2023, are required to create and adhere to a comprehensive plan for managing and sharing their research data, as per NIH data sharing guidelines [8]. As depicted in Fig. 2, the Office of Data Science Strategy at NIH oversees the Generalist Repository Ecosystem Initiative (GREI) [9]. The primary mission of GREI is to establish a unified set of capabilities, services, metrics, and social infrastructure across various generalist repositories. In addition to this, GREI aims to increase general awareness and assist researchers in adopting FAIR principles to enhance data sharing and reuse. Further details can be found in the GREI Workshop Summary Report 2023 [10].
Similarly, F1000 (formerly “Faculty of 1000”) has certain requirements for open data, software, and code (Table 1) [11]. This organization serves as an open research publisher for scientists, scholars, and clinical researchers. It is important to note that F1000Research is an open research publishing platform designed to provide rapid and transparent publication of all research outputs across all disciplines. This platform is recognized as a solution and service provider catering to research scientists, funders, research institutions, societies, and their associations. It offers a rapid and transparent publication of all research outputs, across all disciplines. In January 2020, F1000 was acquired by the Taylor & Francis Group, but it continued to provide publishing services [12].
While there are parallels in the data sharing policies of NIH and F1000, certain differences are also present, as indicated in Table 2 [13]. For example, F1000 offers support and guidance on selecting a data repository and license, among other things, in exchange for the requirement of “using established data repositories for sharing data.” In the webinar, expert speakers Matt Cannon (Head of Open Research, Taylor & Francis Group), Rebecca Grant (Head of Data and Software Publishing, F1000), and Yvette Seger (Director of Science Policy, Federation of American Societies for Experimental Biology [FASEB]) discussed the key considerations that researchers need to address in order to comply with the NIH policy while maximizing the impact of their data, especially when compared to F1000. Regarding all the above factors, determining who will bear the cost and how it will be managed is a critical factor to consider in a data sharing policy.
At the session, Graham Smith presented a new policy regarding data availability statements, titled “Springer Nature: 4 Policy Types to Single Policy.” The data availability statement acts as a crucial connection between a paper’s conclusions and the supporting evidence, which should be grounded in transparency in original research articles. The data availability statement of an article informs the reader about the location and method of accessing data that substantiates the results and analysis. This statement may contain links to publicly accessible datasets that were analyzed or generated during the study, descriptions of the available data, and/or instructions on how to access data that are not publicly available.
Springer Nature has demonstrated its commitment to open science by mandating data availability statements across its entire portfolio of journals and books. It appears that fewer than 40% of authors currently make their data available, likely due to additional burdens and practical challenges, including a lack of clarity about what is required. Nature Portfolio, BMC, and SpringerOpen journals already require a data availability statement in original publications, with BMC being one of the first to implement this requirement.
Springer Nature has requested that the data availability statement should outline how one can access the data that supports the results reported in your paper, as follows [14]:
If your data are in a repository, include hyperlinks and persistent identifiers (e.g., DOI or accession number) for the data where available.
If your data cannot be shared openly, for example to protect study participant privacy, then this should be explained.
Include both original data generated in your research and any secondary data reuse that supports your results and analyses.
Maria Hodges, Executive Editor (BMC and Research Data) commented that “Moving to a single data policy for Springer Nature journals and introducing significantly reduces the complexity of the data policy for authors, helping them to know what is required. It makes clear our commitment to support authors in open research practice and better enable them to benefit from open science.” She continued, “Reproducibility of scientific claims is crucial to the integrity of the scientific record. At the heart of research findings is the data from which results are obtained and conclusions are drawn, and its availability is key in supporting the reproducibility of that research and opening up science to rigorous interrogation.” [15]
The observational study published in the journal Psychological Science by Hardwicke et al. [16] primarily attributed nonreproducibility to the unclear reporting of analytic procedures, emphasizing that open data alone is insufficient to guarantee analytic reproducibility. Consequently, additional measures are necessary to enhance the reusability and analytic reproducibility of scientific manuscripts.
At the end of the session, there was an open discussion about the desirable characteristics of a trustworthy data repository. Several factors were suggested, including unique persistent identifiers, metadata, curation and quality assurance, reusability, reproducibility, the ease of configuring common formats, and provenance.
A session, themed “research integrity” and titled “Stories of Learning from Overcoming Mass Retractions, Systematic Manipulation and Research Misconduct,” involved a discussion among Hannah Smith (Wiley), Yael Fitzpatrick (PNASNews), Luigi Longobardi (IEEE), and Michael Streeter (Wiley). Issues such as plagiarism, data fabrication, conflicts of interest, and authorship disputes frequently challenge research integrity and publication ethics. These are issues that the research and publishing communities need to openly discuss and resolve. By promoting education, transparency, collaboration, and the acknowledgment of responsible practices, the community can work collectively to enhance the system. This will allow for a focus on quality over quantity, ensuring genuine scientific progress for the benefit of society. All publishers and academic societies have been impacted by problems related to research integrity and publication ethics. This is due to the swift expansion of research output and the increasing pressure to publish more papers quickly. The panelists shared their individual and collective experiences to better support industry-wide initiatives. This was done with a wider community of practice across scholarly communities, including publishers, societies, authors, and editors.
In the panelists’ introductions, they noted that their initial professions were quite different from their current roles in research integrity at a publishing house. This is a relatively new career path in the field of ethics, often starting with a volunteer position. Yael Fitzpatrick stated, “The right thing to do is not always the easiest or most pleasant thing to do. For instance, when we have found misconduct and rejected a manuscript, and reported it to the institution.” She went on to describe an instance where a peer reviewer reported a manuscript being submitted to two different publishers. They then had to carefully consider how to address the issue while preserving editorial anonymity.
Luigi Longobardi provided an explanation for the retraction of over 1,000 conference abstracts. Currently, IEEE, the organization in question, is accountable for 25% of all retractions. They received complaints regarding the quality of certain conference abstracts and decided to conduct a thorough investigation, which encompassed 100,000 papers. They did not merely retract these articles; they also closed several chapters and dismissed certain volunteers. For future IEEE conferences, there will be significantly stricter quality requirements and a higher level of technical review. However, Longobardi added, rebuilding trust will inevitably take time.
Michael Streeter from Wiley recently shared a story about the retraction of hundreds of papers from our Hindawi portfolio due to suspected paper mill activities. Yael Fitzpatrick noted, “Publishers are not legally able to conduct investigations, so there is no way for us to confiscate lab books. We are not in charge of it; the research institution is. We also don’t deal with the individuals who are making the charges; instead, we focus on the scholarly record, or publications.”
Following the introduction and brief anecdotes shared by the panelists, a series of questions were posed:
• Q1. How cautiously do you disclose facts about how, say, paper mill activities were discovered? The disclosure of such information could teach fraudsters new tricks.
A1. We do not divulge all of the knowledge we have collected, but we do communicate that we found a paper mill activity (Michael Streeter). It is frustrating that we can retract documents but not the people who profit from these paper factories. In social media marketing, even a Twitter account tweets about fake journals and conferences. Who will find these organizations, though (Luigi Longobardi)?
• Q2. Based on what you learnt, how did your organization learn from that and [what does it now] do differently?
A2. We focus more on tools to investigate image integrity (Yael Fitzpatrick). We introduced new screening tools and guidelines (Michael Streeter). AI tools will be both threat and opportunity (Luigi Longobardi).
• Q3. Does this increased screening include your preprint articles?
A3. Yes, we are looking into policies for that (Luigi Longobardi).
• Q4. What is the future of research integrity and what are you guys most excited about?
A4. Unfortunately, there will be more bad stuff in the future. But I am excited that we will have increased tools against that (Yael Fitzpatrick). There will be potentially more paper mills in the future, but at least that will keep me employed (Luigi Longobardi)! Standardization of workflow of the editorial process will increase screening. And I am excited about collaboration (Michael Streeter).
The session was rife with intrigue and enigma, as evidenced by the numerous retractions of previously published pieces, which particularly piqued my curiosity. Despite this, the session was highly informative, providing valuable insights into the incidents, their repercussions, and future prospects for the development of tools and adherence to guidelines to address issues of integrity.
The session “Locally Sourced, Locally Owned: Independent Society Journal Publishing to Seed Trust and Transformation” examined the advantages of fostering academy-led publishing models, where the publisher is an expert in the field. These models have the potential to catalyze more effective and transparent practices, leveling a playing field that is increasingly dominated by large corporations with fewer incentives to do the same. The session asked two key questions as shown below.
(1) What factors do you consider essential for scholarly societies and institutes to sustainably operate in-house publishing programs like yours?
• Longevity and adaptability are ensured by using a committee to determine the journal’s scope and target audience. Financial stability is essential for continuation. The Journal of Black Excellence in Engineering, Science, and Technology was given financing because it matched the objectives of National Society of Black Engineers (NSBE) and demonstrated the need for equity-focused STEM (science, technology, engineering, and mathematics) research. Success depends on persistence, marketing, and data validation. It took almost 6 years to complete the process (Derius Galvez, Editor-in-Chief of the Journal of Black Excellence in Engineering, Science, and Technology, NSBE).
• To entice authors to publish with the press, RTI Press focuses on finding, utilizing, and communicating its assets to them. RTI Press provides an alternate path for publication rather than going up against established journals and/or bigger publishers. Peer-reviewed forms are offered, such as policy briefs and methods report, to accommodate various research outputs and reach a variety of audiences. Furthermore, RTI Press offers additional flexibility as a small press, enabling customized procedures and solutions catered to authors’ needs. Our Diamond Open Access Publishing strategy, which enables authors without financing to disseminate their findings widely, is one of the primary assets. Authors and RTI decision-makers have backed highlighting these distinct strengths (Anna Wetterberg, Director of RTI Press, RTI International).
(2) How is your team working to increase publishing efficiencies, promote research equity, and provide more value to the academy?
• The journal prioritizes the use of a cutting-edge publishing platform like Scholastica, allowing an efficient publication workflow, to assure a long-lasting and significant presence. We place a strong emphasis on followups and communication as a way to ensure that authors and reviewers have a great experience during the paper solicitation process. A platform for underrepresented STEM students to display their cutting-edge work is provided by the journal’s active participation in engineering research poster competitions at national and regional conventions. The publication sets itself apart by addressing equity concerns in black STEM subjects and attempting to initiate discussions on these topics within the academic community (Derius Galvez).
• RTI Press is committed to maximizing resources in order to improve efficiency and equity. We have focused on making it easier for non-traditional research audiences to access their articles by working with authors to produce videos, blogs, and social media pieces that highlight the key findings. In order to target the right audience, we also promote free educational tools and form alliances with diverse businesses. They have assembled a library of publications on equity in order to address equity-related topics. Additionally, we are actively seeking editorial board members and reviewers from various career stages, geographical locations, academic fields, and research institutions, including a special review board for early career researchers, in order to incorporate diverse expertise and experience into the processes (Anna Wetterberg).
I had a discussion with Amanda Bartell, the Head of Member Experience at Crossref, about how we could enhance integrity in research and publication. We also explored potential future collaborations in this area (Fig. 3). I also had the opportunity to participate in a hybrid panel session titled: “Working Together to Preserve the Integrity of the Scholarly Record in a Transparent Way.” The session was presided over by Amanda Bartell, Head of Member Experience at Crossref, and included panelists Nandita Quaderi, Editor-in-Chief and Vice President of Web of Science; Hylke Koers, Chief Information Officer at STM Solutions; Cheol-Heui Yun, a representative from Seoul National University and Vice President of the Korean Council of Science Editors (KCSE); and Patrick Franzen, Director of Publications and Platforms at SPIE and a COPE (Committee on Publication Ethics) Council Member. The session began by welcoming both the on-site and online audience, as it was conducted in a hybrid format. Following a brief introduction of the panelists and an overview of our roles within the session’s theme, each of us delivered a short presentation. Amanda Bartell initiated the session by highlighting the growing challenges and limitations surrounding research integrity, especially in maintaining the integrity of the scholarly record. She noted that these challenges are escalating due to various factors such as researcher errors, misconduct, dishonest publication practices, plagiarism, image manipulation, the use of chatbots, and paper mills. She pointed out that the scale of the problem has expanded as the scholarly record grows rapidly. For instance, in 2022 alone, 10 million new records were registered with Crossref, including over 6 million new journal articles. This number only represents Crossref members, indicating the enormity of the task of effectively policing scholarly integrity. She also mentioned that advancements in technology, including AI, have amplified deceptive publishing practices to an industrial scale. She then posed the critical questions: “What is the solution to this? And, more importantly, who is responsible?”
Amanda Bartell discussed the role of Crossref in collecting and openly disseminating metadata that can be used as trust signals, and how the Research Nexus is key for everyone in the community to evaluate research. Crossref metadata is integral to maintaining research integrity, ensuring reproducibility, facilitating reporting and assessment, and enhancing discoverability. Crossref improves the visibility and accessibility of research by providing indicators of the work’s reliability. It also fosters connections between literature, data, software, and protocols, and supplies benchmarking data. This makes it easier for others to identify and utilize the work.
In my presentation, I began by providing a brief history of KCSE. I then shifted my focus to the primary activities of the KCSE, with a particular emphasis on the seminars and training programs on publication ethics, a topic that has become particularly important during and after the COVID-19 pandemic.
Nandita Quaderi talked about how Web of Science, as a foundation for trustworthy datasets and metrics, is using rigorous selection in tandem with transparent processes and policies. Hylke Koers delivered a presentation on STM Solutions, the operational arm of the STM Association responsible for creating and managing shared infrastructure and cooperative services to aid STM members and the broader academic community. His talk centered on the STM Integrity Hub (https:// www.stm-assoc.org/stm-integrity-hub/), a collaborative initiative involving over 30 organizations. This initiative facilitates the exchange of expertise and information, and the development of shared solutions to uphold research integrity. The STM Integrity Hub offers publishers a cloud-based platform to scrutinize submitted manuscripts for potential issues related to research integrity. This is done in line with relevant laws and industry best practices, while also fully adhering to data protection and competition and antitrust legislation. In this environment, publishers have the freedom to partner with third parties of their choosing to create and implement screening technologies. This collaboration ultimately benefits the wider scholarly ecosystem.
In his presentation, Patrick Franzen highlighted how COPE is currently uniting publishers and institutions, particularly universities, and underscoring the intersections and commonalities between research integrity and publication integrity.
While there were inquiries from the audience, we also had a set of prearranged questions within our group just in case. Here are some of the questions we had prepared in advance:
(1) What do you think is the biggest challenge in preserving research integrity?
(2) What do you think is a good example of the community working together to preserve research integrity?
(3) Where do you think there is currently a gap—a problem with research integrity that is not being tackled by anyone?
(4) Where should the audience focus their own efforts?
(5) What are publisher’s responsibilities to other publishers, universities, etc.?
(6) How do we share information on potential “bad actors” more effectively?
(7) What should we do with the General Data Protection Regulation in research integrity [as an individual research scientist, journal, or publisher]?
I must admit, it was somewhat overwhelming to absorb all the previously mentioned information within a 2-day meeting. This was especially challenging given the nature of parallel sessions, which prevented me from accessing many of the discussions. Despite now having more questions than before, I am at least reassured that the future of publication and the scholarly community appears promising, with a virtuous cycle emerging among the stakeholders.
In truth, no single community has been able to address the issues previously mentioned. Undeniably, these are the types of problems that require a collaborative effort from all sectors of the community for resolution, leveraging shared knowledge and individual strengths. This could effectively be achieved through practices that are transparent and open.
Notes
-
Conflict of Interest
Cheol-Heui Yun serves as the ethics editor of Science Editing since 2020, but had no role in the decision to publish this article. No other potential conflict of interest relevant to this article was reported.
-
Funding
This work was partially supported by a travel grant from the Korean Council of Science Editors (KCSE) and National Research Foundation of Korea (NRF) (No. NRF2023J1A1A1A01093462).
-
Data Availability
Data sharing is not applicable to this article as no new data were created or analyzed in this study.
Supplementary Materials
The author did not provide any supplementary materials for this work.
Fig. 1.The data life cycle framework for bioscience, biomedical and bioinformatics data. Adapted from Griffin et al. [5], in accordance with the Creative Commons License.
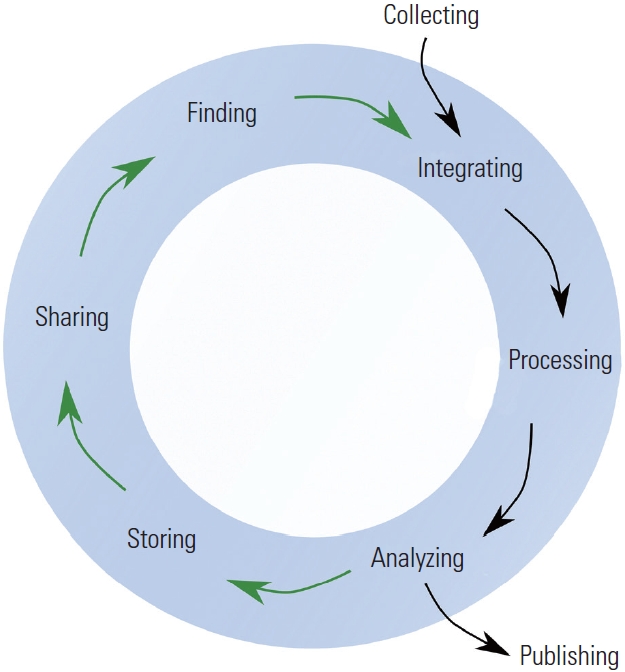
Fig. 2.The objectives of the Generalist Repository Ecosystem Initiative (GREI). Reused from US National Institutes of Health (NIH) [9], in the public domain.
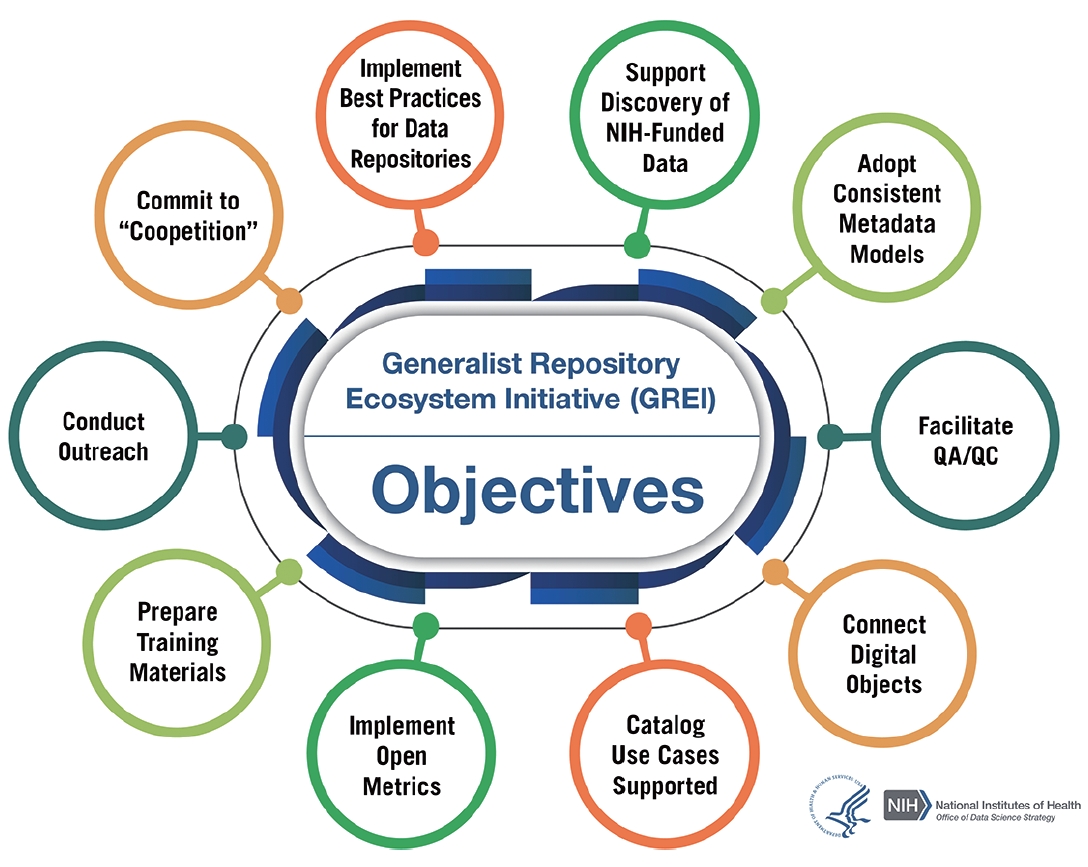
Fig. 3.The author discusses how to enhance integrity in research and publication, and future collaboration with Amanda Bartell (Head of Member Experience, Crossref). Permission for image use granted by Amanda Bartell.

Table 1.Requirements for submitting an article to F1000Research
|
No. |
What is required when submitting an article to F1000Research? |
|
1 |
Your dataset(s) must be deposited in an appropriate data repository. |
|
2 |
Your dataset(s) must have a license applied which allows reuse by others (CC0 or CC-BY). |
|
3 |
Your dataset(s) must have a persistent identifier (e.g., a DOI) allocated by a data repository. |
|
4 |
You must provide a data availability statement as a section at the end of your article, including elements 1–3. |
|
5 |
You must include a data citation and add a reference to data to your reference list. |
|
6 |
Your dataset(s) should not contain any sensitive information, for example in relation to human research participants. |
|
7 |
You should share any related software and code. |
|
8 |
Your dataset(s) must be useful and reusable by others, adhere to any relevant data sharing standards in your discipline and align with the FAIR data principles. |
|
9 |
Your dataset(s) should link back to your article, if possible. |
Table 2.Comparison of the data sharing policies between NIH and F1000
|
Policy element |
NIH |
F1000 |
|
Which data |
All data generated by the research project |
Data underlying the findings of the manuscript |
|
Data management plan |
Required |
Recommended |
|
Informed consent for data sharing |
Strongly encouraged |
Required |
|
Using established data repositories for sharing data |
Strongly encouraged |
Required |
|
Align with FAIR data principles |
Yes |
Yes |
|
Open license |
Not mentioned |
Required |
|
Data citation |
Not mentioned |
Required |
|
Data availability statement |
Not mentioned |
Required |
References
- 1. TNQ Technologies. ChatGPT and other LLMs: should we celebrate or be afraid of these technologies? [Internet]. YouTube; 2023 [cited 2023 Aug 9]. Available from: https://youtu.be/wyx5xudczjo.
- 2. Center for AI Safety (CAIS). Statement on AI risk [Internet]. 2023; [cited 2023 Aug 9]. Available from: https://www.safe.ai/statement-on-ai-risk.
- 3. Nelson A. Memorandum for the heads of executive departments and agencies [Internet]. US Office of Science and Technology Policy (OSTP); 2022 [cited 2023 Aug 9]. Available from: https://www.whitehouse.gov/wp-content/uploads/2022/08/08-2022-OSTP-Public-access-Memo.pdf.
- 4. US National Institutes of Health (NIH). Writing a data management & sharing plan [Internet]. NIH; 2023 [cited 2023 Aug 9]. Available from: https://sharing.nih.gov/data-management-and-sharing-policy/planning-and-budgeting-for-data-management-and-sharing/writing-a-data-management-and-sharing-plan.
- 5. Griffin PC, Khadake J, LeMay KS, et al. Best practice data life cycle approaches for the life sciences [version 2; peer review: 2 approved]. F1000Res 2018;6:1618. https://doi.org/10.12688/f1000research.12344.2. ArticlePMC
- 6. Boeckhout M, Zielhuis GA, Bredenoord AL. The FAIR guiding principles for data stewardship: fair enough? Eur J Hum Genet 2018;26:931. – https://doi.org/10.1038/s41431-018-0160-0. ArticlePubMedPMC
- 7. Carroll SR, Garba I, Figueroa-Rodríguez OL, et al. The CARE Principles for Indigenous Data Governance. Data Sci J 2020;19:43. https://doi.org/10.5334/dsj-2020-043. Article
- 8. Taylor & Francis. NIH data sharing: a researcher’s guide to compliance and increasing impact [Internet]. Taylor & Francis; 2023 [cited 2023 Aug 9]. Available from: https://authorservices.taylorandfrancis.com/events/nih-data-sharing-a-researchers-guide-to-compliance-and-increasingimpact/.
- 9. US National Institutes of Health (NIH). Generalist Repository Ecosystem Initiative [Internet]. NIH; 2023 [cited 2023 Aug 9]. Available from: https://datascience.nih.gov/data-ecosystem/generalist-repository-ecosystem-initiative.
- 10. Gulick AV, Pfeiffer N, Chandramouliswaran I, et al. Generalist Repository Ecosystem Initiative (GREI) workshop. Zenodo 2023;https://doi.org/5281/zenodo.7714262. Article
- 11. F1000Research. How to publish: open data, software and code guidelines [Internet]. F1000Research; c2023 [cited 2023 Aug 9]. Available from: https://f1000research.com/for-authors/data-guidelines.
- 12. Price G. Scholarly publishing: Taylor & Francis acquires F1000 Research. Library Journal infoDOCKET; 2020 [cited 2023 Aug 9]. Available from: https://www.infodocket.com/2020/01/10/scholarly-publishing-taylor-francis-acquires-f1000-research/.
- 13. F1000. NIH data sharing: a researchers guide to compliance and increasing impact [Internet]. YouTube; 2023 [cited 2023 Aug 9]. Available from: https://www.youtube.com/watch?v=44V7oPxS9xY.
- 14. Springer Nature. Research data policy: data availability statements [Internet]. Springer Nature; c2023 [cited 2023 Aug 9]. Available from: https://www.springernature.com/gp/authors/research-data-policy/data-availability-statements.
- 15. Springer Nature. Springer Nature makes data sharing easier with single data policy across all journals and books [Internet]. Springer Nature; 2023 [cited 2023 Aug 9]. https://group.springernature.com/gp/group/media/press-releases/springer-nature-makes-data-sharing-easier-with-singlepolicy/25211176.
- 16. Hardwicke TE, Bohn M, MacDonald K, et al. Analytic reproducibility in articles receiving open data badges at the journal Psychological Science: an observational study. R Soc Open Sci 2021;8:201494. https://doi.org/10.1098/rsos.201494. ArticlePubMedPMC
Citations
Citations to this article as recorded by




 PubReader
PubReader ePub Link
ePub Link Cite
Cite